


Server virtualization is changing how AI and HPC environments run behind the scenes. Think you need a warehouse full of hardware to handle massive AI workloads. Not anymore. With the latest virtualization advances, companies are now cutting their physical server needs so much that some report up to 40 percent greater resource utilization just from dynamic VM provisioning alone. The real shock is how these virtual solutions deliver near-native GPU speed while slashing costs and energy use at the same time. That shift is rewriting every rule about where and how cutting-edge computing happens.
| Takeaway | Explanation |
|---|---|
| Server virtualization boosts AI computational efficiency. | Virtualization allows dynamic resource allocation, optimizing GPU and CPU power for AI workloads while minimizing waste. |
| Maximizes resource utilization and reduces costs. | By consolidating VMs on fewer physical servers, organizations save on hardware and energy costs significantly. |
| Enables rapid provisioning and operational flexibility. | Virtual machines can be migrated easily, allowing quick deployment and minimizing downtime during maintenance. |
| Advanced GPU virtualization enhances performance. | New technologies allow the sharing of GPUs between VMs with minimal performance loss, achieving near-native speeds. |
| Adopt best practices for effective virtualization. | Strategies like topology-aware configurations and dynamic resource management can vastly improve virtualization efficiency. |
Server virtualization has become a critical enabler for modern AI and high-performance computing (HPC) environments, transforming how computational resources are allocated and managed. By creating multiple virtual machines (VMs) on a single physical server, organizations can dramatically improve resource utilization, flexibility, and cost-effectiveness for complex AI workloads.
Resource Optimization and Dynamic Allocation
AI workloads demand extraordinary computational flexibility, and server virtualization provides precisely that capability. Research exploring adaptive resource management demonstrates how virtualization enables dynamic adjustment of computing resources in real-time. Organizations can now allocate GPU and CPU resources more intelligently, ensuring that machine learning models receive exactly the computational power they require without wastage.
The adaptive resource management techniques allow AI infrastructure to respond dynamically to changing computational demands. For instance, during training phases of neural networks, virtualization platforms can instantly redistribute resources, scaling up GPU allocations when intensive matrix computations are needed and scaling down during less demanding processing stages.
GPU virtualization technologies have revolutionized how computational acceleration is delivered across virtual environments. These advanced techniques enable near-native performance by allowing GPUs to be shared among multiple virtual machines with minimal overhead. This means AI researchers and data scientists can run complex deep learning models across virtualized infrastructure without sacrificing processing speed.
The mediated pass-through techniques developed in recent years ensure that virtualized environments can now achieve performance levels approaching bare-metal configurations. This breakthrough eliminates previous concerns about performance degradation that once made virtualization less attractive for compute-intensive AI workloads.
Server virtualization introduces unprecedented architectural flexibility for AI computing infrastructures. By decoupling software environments from underlying hardware, organizations gain the ability to rapidly provision, migrate, and replicate complex AI development and deployment environments. Studies on server allocation strategies highlight how virtualization enables more responsive and efficient resource management, improving overall system Quality-of-Service parameters.
This architectural agility means AI teams can quickly spin up isolated environments for different stages of machine learning model development, from experimental prototyping to large-scale training and inference. The ability to create consistent, reproducible computing environments accelerates innovation and reduces technical friction in AI research and development.
For enterprises and research institutions pushing the boundaries of artificial intelligence, server virtualization is no longer just a technological convenience—it has become an essential infrastructure strategy. By providing unprecedented resource optimization, computational efficiency, and architectural flexibility, virtualization technologies are quietly but fundamentally reshaping how advanced AI workloads are conceived, developed, and deployed.
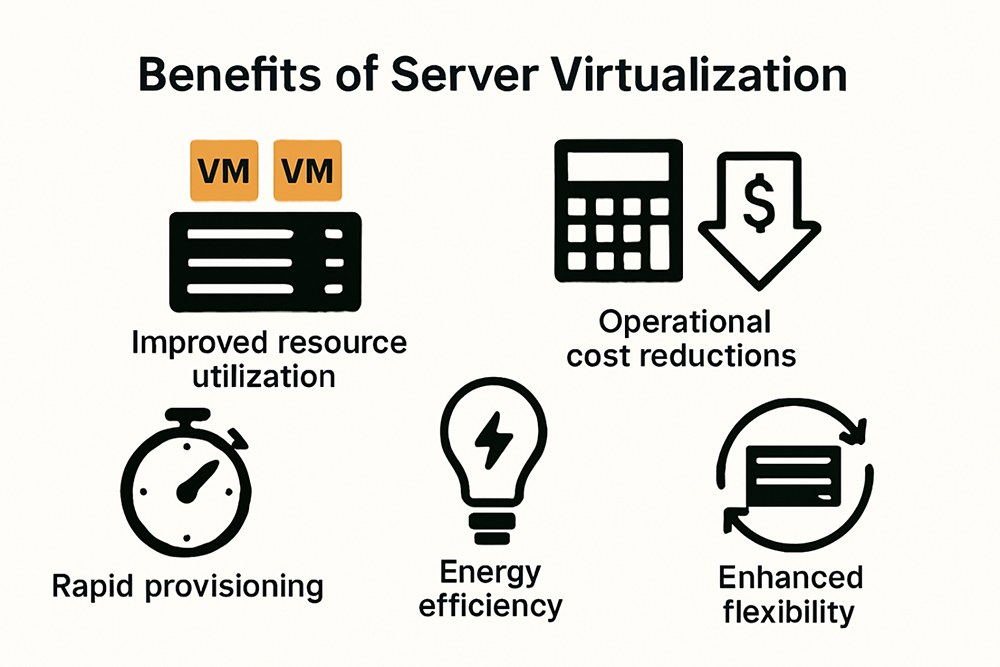
Server virtualization has emerged as a transformative technology for high-performance computing (HPC) and enterprise data centers, offering unprecedented advantages in resource management, operational efficiency, and strategic infrastructure optimization. Explore the comprehensive guide to HPC infrastructure to understand the full potential of these innovations.
Enterprise data centers face constant pressure to reduce operational costs while maintaining high computational performance. According to Energy Star research, server virtualization enables organizations to dramatically improve hardware utilization rates. By consolidating multiple virtual machines on a single physical server, companies can reduce the total number of physical servers required, leading to significant energy savings and reduced hardware investment.
The economic benefits extend beyond initial hardware costs. Virtualization allows for more efficient power consumption, cooling requirements, and physical space utilization. Data centers can now support more computational workloads with fewer physical resources, translating into substantial long-term operational cost reductions.
To provide a clear overview, the table below summarizes the key benefits of server virtualization for HPC and enterprise data centers as described in this section.
| Benefit Area | Description |
|---|---|
| Resource Utilization | Consolidates VMs, improves hardware use, reduces total number of physical servers |
| Cost Efficiency | Saves on hardware investment, power, and cooling leading to long-term operational cost reductions |
| Operational Flexibility | Enables quick provision, migration, and cloning of virtual environments with minimal downtime |
| Performance & Scalability | Supports granular allocation for mixed workloads (AI, simulations, analytics) on the same infrastructure |
| Security & Compliance | Facilitates isolated environments enabling control, monitoring, and enforcement of policies |
Research from university IT infrastructure studies highlights the unparalleled flexibility virtualization brings to enterprise computing environments. Virtual machines can be seamlessly migrated across different hosts, enabling rapid deployment, quick provisioning of new servers, and minimized downtime during maintenance or hardware upgrades.
This architectural flexibility is particularly crucial for HPC environments, where computational demands can fluctuate rapidly. Virtualization provides a dynamic infrastructure that can instantly reallocate resources, ensuring optimal performance for complex workloads. The ability to create, clone, and recover entire computing environments with minimal disruption represents a quantum leap in operational resilience.
Insights from HPC technology experts reveal that virtualization is no longer just a cost-saving measure but a strategic enabler of advanced computational capabilities. For enterprise data centers dealing with AI, machine learning, and complex scientific computing, virtualization offers unprecedented scalability and performance optimization.
The technology allows for granular resource allocation, enabling precise tuning of computational resources across different workloads. This means AI training jobs, scientific simulations, and big data analytics can coexist on the same physical infrastructure, with each receiving exactly the computational resources required for optimal performance.
Moreover, virtualization introduces a layer of abstraction that enhances security and compliance. By creating isolated environments, enterprises can implement robust access controls, network segmentation, and advanced monitoring capabilities that were challenging to achieve in traditional physical server architectures.
As enterprise computing continues to evolve, server virtualization stands at the forefront of technological innovation. It represents more than a technical solution—it’s a strategic approach to building flexible, efficient, and powerful computational infrastructures that can adapt to the rapidly changing demands of modern digital enterprises.
The convergence of server virtualization and advanced GPU technologies is reshaping the landscape of high-performance computing and artificial intelligence infrastructure in 2025. Discover the latest HPC infrastructure trends to understand the cutting-edge developments driving this transformation.
NVIDIA and VMware’s collaborative effort has introduced the VMware Private AI Foundation, a groundbreaking solution that enables enterprises to deploy AI workloads with unprecedented flexibility and security. This platform leverages VMware Cloud Foundation and integrates seamlessly with NVIDIA’s advanced GPU technologies, creating a robust ecosystem for complex computational tasks.
The solution supports a wide range of enterprise-grade servers from leading manufacturers, including Dell Technologies, Hewlett Packard Enterprise, Lenovo, Supermicro, and Fujitsu. By providing a standardized approach to AI infrastructure, these platforms dramatically reduce the complexity of deploying and managing high-performance computing environments.
The following table summarizes the main virtualization solutions and advanced GPU server configurations highlighted in this section.
| Category | Example/Platform | Key Features & Innovations |
|---|---|---|
| Virtualization Platform | VMware Private AI Foundation with NVIDIA | Integrates with NVIDIA GPUs; flexibility, security, scalability |
| GPU Server Ecosystem | NVIDIA-Certified HGX Systems | 8x H100/H200 GPUs, NVSwitch, NVLink, BlueField-3 DPUs |
| Software Stack | NVIDIA AI Enterprise Software | Enhanced security, performance isolation, precise allocation |
| Supported Server Vendors | Dell, HPE, Lenovo, Supermicro, Fujitsu | Wide ecosystem, enterprise-grade support |
| Key Technologies | Machine learning-driven management | Real-time resource allocation, optimization, compliance |
NVIDIA’s latest server ecosystem showcases remarkable advancements in GPU virtualization and server design. The NVIDIA-Certified HGX systems now feature sophisticated configurations with 8x H100 or H200 GPUs, integrated NVSwitches, and NVLinks that enable high-speed inter-GPU communication. These configurations are specifically engineered to support complex AI workloads, including generative AI model training and inference.
Key innovations include the integration of NVIDIA BlueField-3 DPUs and NVIDIA AI Enterprise software, which provide enhanced security, performance isolation, and precise resource allocation across virtualized environments. This approach allows enterprises to fine-tune foundation models and deploy sophisticated AI applications with unprecedented granularity and control.
The virtualization landscape in 2025 is characterized by a shift towards more intelligent, adaptive infrastructure solutions. Modern platforms now incorporate machine learning-driven resource management, enabling dynamic allocation of computational resources based on real-time workload demands. These systems can automatically balance GPU utilization, optimize memory allocation, and maintain performance consistency across complex, multi-tenant computing environments.
Security and compliance have become central considerations in virtualized GPU infrastructures. Advanced platforms now provide robust isolation mechanisms, allowing organizations to create secure, compliant environments for sensitive AI workloads. Features like granular access controls, encrypted VM migrations, and comprehensive audit trails have become standard expectations for enterprise-grade virtualization solutions.
As artificial intelligence continues to push the boundaries of computational complexity, server virtualization technologies are evolving to meet increasingly sophisticated requirements. The convergence of hardware innovation, intelligent software management, and flexible infrastructure design is creating a new paradigm for high-performance computing that promises to accelerate technological innovation across multiple domains.
As server virtualization becomes increasingly complex, organizations must adopt strategic approaches to maximize performance, efficiency, and resource utilization in high-performance computing environments. Learn more about advanced HPC infrastructure strategies to understand the critical nuances of optimizing virtualized systems.
Topology-Aware VM Configuration
NVIDIA’s comprehensive virtualization guidelines emphasize the critical importance of topology-aware virtual machine configurations. In AI and high-performance computing environments, the communication pathways between virtual machines can significantly impact overall system performance. Misaligned VM topologies can introduce latency, reduce data transfer efficiency, and ultimately compromise computational performance.
Effective topology management requires careful mapping of virtual resources to physical infrastructure. This involves understanding the underlying hardware architecture, ensuring that VMs are strategically placed to minimize communication overhead, and leveraging advanced networking technologies that support high-bandwidth, low-latency interconnects. By implementing intelligent topology strategies, organizations can dramatically improve the performance of complex computational workloads.
Research from the Multiverse Project reveals groundbreaking approaches to dynamic VM provisioning in high-performance computing clusters. The study demonstrates that advanced provisioning techniques, such as instant cloning, can reduce VM deployment times and improve resource utilization by up to 40%. This approach allows organizations to create more responsive and adaptive computing infrastructures that can rapidly scale to meet changing computational demands.
Configuration management plays a pivotal role in this dynamic environment. Insights from Puppet’s HPC configuration research highlight the importance of maintaining a consistent and desired infrastructure state. By implementing robust configuration management strategies, organizations can ensure that their virtualized environments remain optimized, secure, and predictable, even as workloads and resource requirements evolve.
The table below summarizes the best practices mentioned for maximizing virtualization efficiency in HPC and AI environments.
| Best Practice | Purpose/Benefit | Related Technology/Approach |
|---|---|---|
| Topology-Aware VM Configuration | Minimize latency, improve communication and performance | Hardware-aware VM placement |
| Dynamic Resource Provisioning | Optimize resource use, reduce deployment times (up to 40%) | Instant cloning, adaptive scheduling |
| Configuration Management | Ensure infrastructure consistency, security, predictability | State enforcement, Puppet, automation |
| Intelligent Workload Scheduling | Predict resource needs, optimize allocation | Data-driven algorithms |
| Performance Isolation | Prevent contention, guarantee stable performance | Security, robust VM boundaries |
| Energy-Efficient Management | Balance compute performance with lower power usage | Power-aware provisioning |
Maximizing virtualization efficiency requires a holistic approach that goes beyond simple resource allocation. Organizations must implement sophisticated monitoring and optimization techniques that provide granular insights into system performance. This includes real-time resource tracking, predictive workload analysis, and automated optimization mechanisms that can dynamically adjust resource allocations based on computational demands.
As artificial intelligence and high-performance computing continue to push the boundaries of computational complexity, virtualization efficiency will become increasingly critical. Organizations that can master these advanced configuration and optimization techniques will gain a significant competitive advantage, enabling them to build more responsive, efficient, and powerful computing infrastructures.
The future of server virtualization lies not just in technological capabilities, but in the intelligent, strategic management of computational resources. By embracing these best practices, enterprises can transform their virtualized environments from mere infrastructure components into dynamic, adaptive computational ecosystems that drive innovation and technological advancement.

Server virtualization allows multiple virtual machines (VMs) to run on a single physical server, optimizing resource utilization and flexibility. This technology enables dynamic resource allocation, ensuring AI workloads receive the necessary computational power without waste.
Server virtualization consolidates multiple VMs on fewer physical servers, significantly reducing hardware needs. This consolidation leads to increased resource utilization by allowing better distribution and management of computing resources, ultimately lowering costs and energy consumption.
GPU virtualization allows multiple virtual machines to share GPU resources while maintaining near-native performance levels. This capability enhances the computational efficiency of AI applications, enabling faster processing of complex tasks without sacrificing speed or performance.
To maximize virtualization efficiency, organizations should implement topology-aware VM configurations, dynamic resource provisioning, and robust configuration management. These practices ensure better performance, lower latency, and optimized resource allocation across AI and HPC workloads.
Unlocking peak server virtualization efficiency means more than just understanding best practices. It requires rapid access to powerful, scalable GPU infrastructure the moment your project demands change. If you are facing hardware bottlenecks, cost challenges, or unpredictable compute loads as outlined in our guide, it is time to connect your insights to real-world action. The pain points explored here—from resource optimization and dynamic VM allocation to near-native GPU speeds—are exactly what our marketplace is built to solve.
Act now to eliminate the guesswork and delays that slow your advancements. At NodeStream by Blockware Solutions, you can instantly browse real-time inventory of GPU servers and AI-ready HPC equipment, whether you aim to scale up, right-size, or liquidate surplus. Enjoy complete transparency, verified listings, and expert logistical support on every transaction. Take the next step by visiting our homepage and experience what near-instant, enterprise-grade procurement feels like for server virtualization, AI, and HPC transformation. Your future-proof infrastructure is just a click away.

AI computing is quietly redrawing the boundaries of crypto, finance, and high-performance computing. Brace yourself. By…
Artificial intelligence is turbocharging the world of finance as never before, shaking up how both…
Digital transformation is about to completely reshape how we use crypto and artificial intelligence in…


